
Python自动登录武汉大学校园网
起因:为了让树莓派能自动连接上校园网,研究了一下校园网的登录方式,在此记录一下。
思路:抓包校园网的登录过程,再用python模拟一下即可。
wireshark抓包分析

使用http and ip.dst == 172.19.1.9来筛选连接到校园网的http包,右键follow来查看http内容。
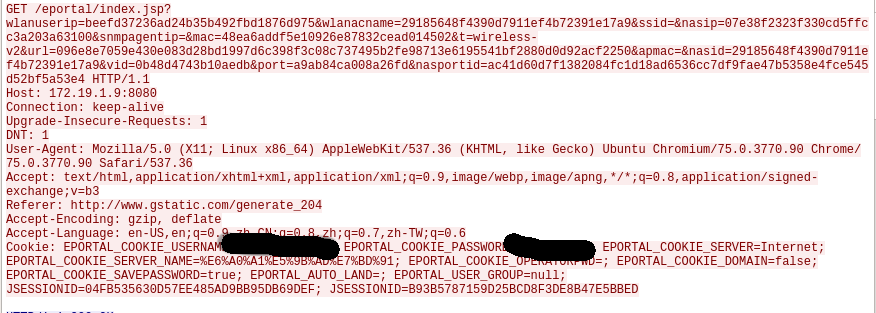
可以发现GET方法的url含很多参数,如wlanuserip等,并且值是加密的,还要用到cookies。
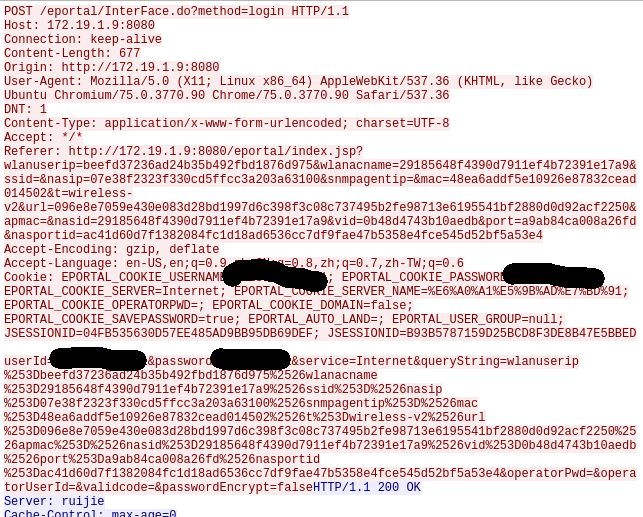
登录之后可以看到POST方法的url是http://172.19.1.9:8080/eportal/InterFace.do?method=login,用到的cookies和前面一样,并且得到了POST方法的数据键名,对比看出queryString的值是GET方法的url的参数的urlencode。
需求
只需要获得GET方法url的参数和cookies即可。由于没登录时任意打开一个网站都会跳转到登录页面,最终页面的url就含有需要的参数,并且推测会返回cookies。
故只需要获得最终页面的response即可,正好python的requests库默认跟随跳转且记录中途responses。
跳转比较慢,需要设置一下超时时限。
没想到response的history列表居然为空,最后发现它第一个response就含有我心心念念的url。
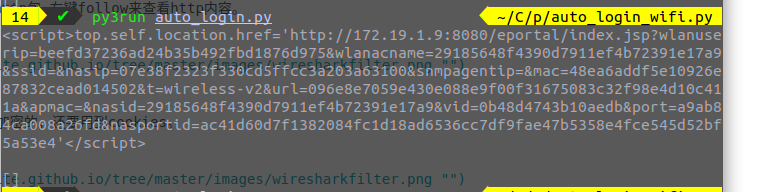
检验一下response的cookies,果然有。
完整代码
import requests
import urllib.parse
start_url = 'http://www.baidu.com'
post_url = "http://172.19.1.9:8080/eportal/InterFace.do?method=login"
my_headers = {
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/75.0.3770.90 Chrome/75.0.3770.90 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': '*/*',
'Referer': start_url,
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7,zh-TW;q=0.6'
}
# get url with parameters
get_response = requests.get(start_url, headers=my_headers, timeout=None)
text = get_response.text
get_url = text[text.index('href')+6:text.index('</script')-1]
print(get_url)
some_info = get_url[get_url.index('wlanuserip'):]
# update headers with some info
my_headers['Referer'] = get_url
# get cookies
r = requests.get(get_url, headers=my_headers, timeout=None)
my_cookies = requests.utils.dict_from_cookiejar(r.cookies)
print(my_cookies)
my_data = {
'userId': 'your_student_id',
'password': 'your_password',
'service': 'Internet',
'queryString': urllib.parse.quote(some_info),
'operatorPwd': '',
'operatorUserId': '',
'validcode': '',
'passwordEncrypt': 'false'
}
r = requests.post(post_url, data=my_data, headers=my_headers, cookies=my_cookies)
print(r.text)
Written on July 5, 2019